
Notice
Recent Posts
Recent Comments
Link
Love Every Moment
〔모두를 위한 파이썬〕딕셔너리, 데이터 빈도수 측정하기 본문
반응형


1. 딕셔너리
- 순서가 없는 가방과 같은 개념
- 물건에 라벨을 붙여놓으면 다음에 그 물건을 찾기가 쉽다! (key - value)
- purse = dict() 로 빈 딕셔너리를 생성
- purse['money'] = 12 와 같이 사용

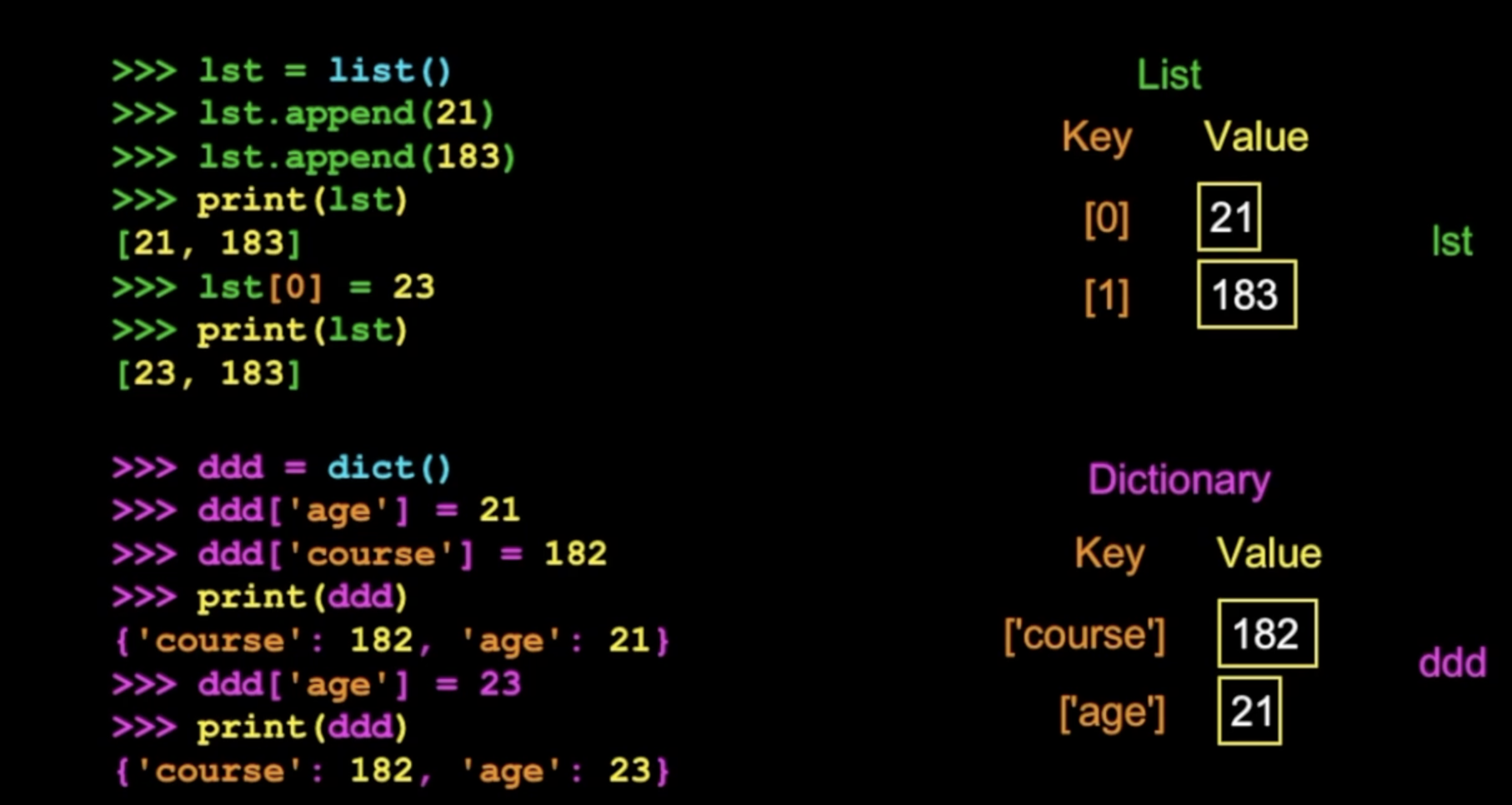
2. 리스트와 딕셔너리의 차이
- 리스트는 lst[0] 처럼 숫자를 키로 사용
- 딕셔너리는 ddd['age'] 처럼 숫자 대신 문자열을 키로 사용

3. 딕셔너리의 특징
- 프린트 하면 딕셔너리의 내용물을 그대로 똑같이 출력해준다


4. 딕셔너리 내용물 개수 세기
- ccc['cwen'] = ccc['cwen'] + 1 처럼 카운트를 증가
- 하지만, 문제는 딕셔너리에 아직 존재하지 않는 키를 참조하는 것은 오류를 발생시킨다는 것!

(1) 첫번째 해결 방법: in
- in 논리 연산자를 이용하여 딕셔너리에 해당 키가 있는지 검사하고,
- 없다면 counts[name] = 1 처럼 새롭게 추가


(2) 두번째 해결 방법: get
- get 메서드를 사용하여 딕셔너리명.get(키, 디폴트) 의 형식으로 딕셔너리에 키가 존재하는지 검사한 다음,
- 없다면 두번째 인자로 넘겨준 값으로 초기화 해준다


5. key/value 추출하기
- 왼쪽 사진은 for 루프를 이용해 print(key, value) 의 형식으로 모든 키와 값을 출력
- 오른쪽 사진은 메서드를 활용하여 딕셔너리의 키와 값을 각각 또는 동시에 추출하는 방법
- list(딕셔너리)를 하면 키만을 가지고 리스트로 만들어 반환하며, 딕셔너리.keys() 역시 동일한 결과를 가져온다
- 딕셔너리.values() 는 값만을 가지고 리스트로 만들어 반환
- 딕셔너리.items() 는 키와 값 모두를 가지고 리스트로 만들어 반환
여기서 items() 가 반환하는 키와 값이 쌍을 이루는 자료구조를 '튜플(Tuple)' 이라고 한다

- 여기서 items() 가 키와 값을 모두 리스트화 한다고 하였으므로,
- 파이썬만이 가지는 두 개의 iteration variable 을 가지고 루프를 돌 수 있다는 특징을 이용해 key - value 쌍을 출력 가능

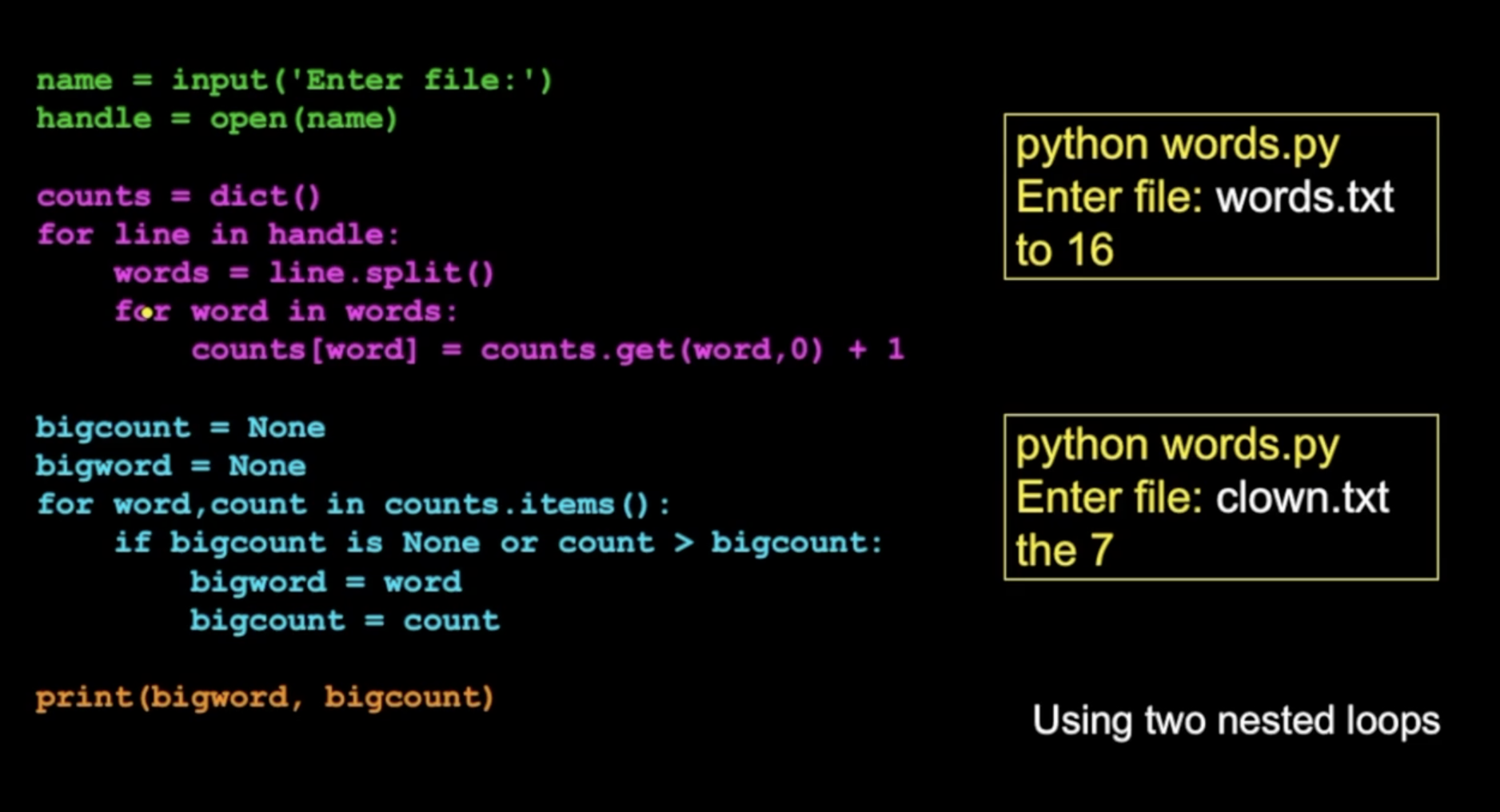
6. 딕셔너리로 데이터 빈도수 측정하기
- 위에서 배운 split(), get(), items() 을 활용하여 대용량 파일의 데이터 빈도수도 쉽게 셀 수 있다
- 오른쪽 사진은 가장 자주 등장한 단어의 등장 횟수와 무슨 단어인지 찾아내는 코드이다
7. 실습하기
fname = input('Enter File: ')
if len(fname) < 1 : fname = 'clown.txt'
hand = open(fname)
di = dict()
for lin in hand :
lin = lin.rstrip()
wds = lin.split()
# 현재 단어 딕셔너리에 저장
for w in wds :
di[w] = di.get(w,0) + 1
# 가장 자주 등장한 단어 찾기
# largest: 가장 자주 등장한 단어 횟수
# theword: 가장 자주 등장한 단어
largest = -1
theword = None
for k, v in di.items() :
print(k,v)
if v > largest :
largest = v
theword = k
print(theword, largest)
강의 사이트
모두를 위한 파이썬 (PY4E)
부스트코스 무료 강의
www.boostcourse.org
반응형
'PROGRAMMING::LANGUAGE > Python' 카테고리의 다른 글
| 〔백준/파이썬〕10809번 알파벳 찾기 (0) | 2022.06.24 |
|---|---|
| 〔모두를 위한 파이썬〕튜플, 가장 빈도가 높은 단어 찾기 (0) | 2022.06.24 |
| 〔모두를 위한 파이썬〕리스트, split() 으로 원하는 부분 추출하기, 가디언 패턴 (0) | 2022.06.23 |
| 〔백준/파이썬〕1065번 한수 (0) | 2022.06.23 |
| 〔백준/파이썬〕4673번 셀프 넘버 (0) | 2022.06.23 |
'PROGRAMMING::LANGUAGE/Python' Related Articles
more




Comments